






Special Feature
SnowflakeとDatabricks 新たなデータ活用ソリューションとして注目される理由
2020/11/19 09:00




週刊BCN 2020年11月16日vol.1850掲載
Databricks
AI、機械学習のためのビッグデータ基盤
SparkベースでDWHとデータレイクのいいとこ取り
米データブリックスは、Apache Sparkの生みの親であるマテイ・ザハリア氏とアリ・ゴディシ氏が2013年に設立した。そもそものSparkは、異常気象などの地球規模の問題を解決するために膨大なデータを分析する必要があり、その解決策として生み出された。Sparkは社会貢献を目的としオープンソース・ソフトウェアとして公開される。それと並行して、ビジネス領域ではAIや機械学習に特化したプラットフォームのニーズが生まれ、Sparkをベースにした商用実装としてDatabricksが生まれた。
「DWHで機械学習をやろうとすると難しいものがある」と指摘するのは、データブリックスジャパンの竹内賢佑・カントリーマネージャーだ。機械学習用のデータを扱うには、非構造化データなども扱えるデータレイクが別途必要となる。DWHとデータレイクの両方が存在すると、データ基盤の構成は複雑化し、データサイエンティストが必要な情報をすぐに取りだして活用するのは難しくなる。これに対しDatabricksでは、「レイクハウス」を提供する。「レイクハウスはDWHとデータレイクの優れたところを一つにして提供するもの」と竹内カントリーマネージャーは説明する。構造化・半構造化・非構造化のデータを活用したいニーズに対し、Databricksは単一のプラットフォームで対応しているのだ。

米調査会社ガートナーは、5年ほど前に「ロジカルDWH」という概念を提唱している。全ての分析要求に対し、大規模なDWH一つでは性能不足やデータの多様性に応えられず、現実的ではない。そこで一つに集約するのではなく、さまざまなデータベースやHadoopなどを論理的に組み合わせて、あたかも一つのDWHがあるようにするのだ。それをクラウドに対応したマネージドサービスで提供するのがDatabricksというわけだ。Databricksは、全てのデータ、全てのユーザーのあらゆるユースケースに対応する。バッチ処理もでき、ストリームデータも扱える。
「オープン、マルチクラウド、従量課金制、そして高速というのが、Databricksの特徴だ」と言うのは、データブリックスジャパンの竹下俊一郎・パートナー・ソリューション・アーキテクトだ。Databricksはプライベートクラウドでも利用できるが、クラウドベンダーと密接に連携しているところが肝。実際ほとんどの顧客が、パブリッククラウドの上でDatabricksを利用しているという。

データ基盤とMLOps環境を
ワンストップで提供
パブリッククラウドでDatabricksを利用することで、データ蓄積部分にはAmazon S3やAzure Blob Storageなどのオブジェクトストレージを用いて、大量のデータを安価で効率的に貯められる。その上にデータを読み書きする「DELTA LAKE」があり、ここではACIDで高品質なトランザクション機能を提供しつつ、ストリームデータも扱えるようにしている。その上にはデータを計算するのに利用する「DELTA ENGINE」が用意されており、並列計算によって高速な処理が可能となっている。
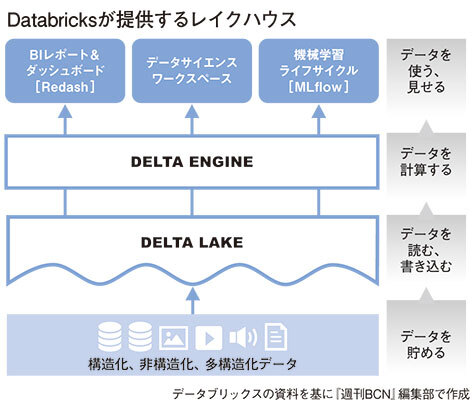
このユニークなアーキテクチャーで実現されているDatabricksのレイクハウスは、一般的なクラウドDWHと比較して、「BIやダッシュボード、アドホック分析などのビジネス分析領域に加え、データエンジニアリング、データサイエンス領域のニーズにも応えられる」「SQLに加えPython、Scala、Java、Rなどの多様な言語にネイティブに対応する」「構造・半構造・非構造など全てのデータに対応する」「バッチワークロード、ストリーミングワークロードをサポートする」「クラウドストレージにオープン形式でデータを格納し、安価でベンダーロックインがない」という五つの優位性がある。
Databricksでは、買収などでポートフォリオをさらに拡大している。BIダッシュボードの「Redash」を買収で手に入れ、データサイエンティストが機械学習モデルの管理をするための「データサイエンスワークスペース」も用意している。そして機械学習全体のライフサイクル管理でMLOps(機械学習の開発チームと運用チームの連携)を実現する「MLflow」もある。これらを使えば、AI・機械学習環境の構築から継続的な運用を一つのプラットフォームで対応できる。ユーザーは、Databricksの裏側にあるSparkをベースとした仕組みがどう動いているかを意識する必要はない。マネージドサービスとして提供され「HadoopやSparkを用いて苦労してきたデータレイクのクラスタの運用などは一切必要ない」と竹下氏は言う。
Sparkの技術を活用しているので、性能要求に応じノードのスケールアップ/ダウンを自動的に行える。これにより必要なときに最高性能を得られると同時に、利用していないときにはノードを減らしコストを最適化できる。現状は、オンプレミスのHadoopデータレイクをクラウド上のDatabricksに移行する例がある。またAWSの上で動かしていたHadoop環境をAWS上のDatabricksのマネージドサービスに移行する例もある。また、機械学習を使いこなすためのデータ基盤として、クラウド上にDatabricksのレイクハウスを新たに構築する例も増えているという。
日立ソリューションズは、日本法人が本格活動する前からDatabricksに注目してきた。同社ではHadoopなどを用いたデータレイクを構築し、データ利活用ソリューションの導入を進めてきた。昨今は顧客のクラウドシフトを強力に進めており、クラウド向けに迅速かつ効率的に導入するため、「データ利活用 クラウド基盤導入ソリューション for Databricks」の提供に至った。潜在的な顧客にはデータ活用についての環境面の課題だけでなく、そもそもどのような活用方法があるかに頭を悩ませているケースも多い。このソリューションではオンプレミスでの経験を生かしDatabricksのデータ活用基盤をクラウドで構築するだけでなく、顧客のデータ活用全体を支援するものとなる。
日立ソリューションズでは、すぐに始められること、データ量の増加、多様化に柔軟に対応できること、運用が容易なことを重視し、これら全ての条件を満たす最適なサービスがDatabricksだと判断した。さらにこれまで扱ってきたHadoop、Sparkの技術を生かせることも、採用の大きなポイントとなった。今後はDatabricksを使いトライアルできる環境を提供し、そこで顧客のデータを用いデータ分析のトライ&エラーを顧客と一緒に推進するサービスを考えているとのこと。その上でDatabricksと他製品も組み合わせて、プレパレーションやデータガバナンスも含めクラウド環境におけるデータ活用全般をトータルにサポートしていく。
パートナーエコシステムを
日本では重視
ところで、DatabricksとSnowflakeは競合するのだろうか。市場では同じ領域のものと捉えられることも多いが、データブリックスではSnowflakeをクラウドDWH製品と考えており「かぶるところはあるが、別もので共存できると思っている」と竹下アーキテクトは話す。その上で、Databricksはこれまで技術色が強く理解してもらうのが難しい面もあったが、レイクハウスの概念でよりSnowflakeとの違い、その価値が伝わりやすくなるはずだとも言う。
日本でレイクハウスの価値を伝えるために、同社もパートナーエコシステムを強化する。クラウドパートナーにはマイクロソフトやAWSなどがあり、テクノロジーパートナーにはタブロー(Tableau)やクリック(Qlik)、インフォマティカ(Informatica)などがある。さらにデータ活用のコンサルティングができるアクセンチュアやNTTデータ、日立ソリューションズがあり、彼らとのパートナーエコシステムで顧客にアプローチする。
さらにエコシステムには日本企業に深く入り込んでいるような、中小規模のSI企業も今後は積極的に取り込む。「日本のデジタル変革はまだ遅れており、それが最初に動くのはアウトソーシングがきっかけになるはずだ。その部分をさまざまなパートナーと一緒に進める」と竹内カントリーマネージャー。さらに経営層へのデータ活用の啓蒙にも力を入れる。そして「Databricksがギーク用のツールではなく、『AIの民主化』とそのための『データの民主化』に貢献できる、というメッセージの発信にも力を入れる」としている。

企業によるデータ活用がITの重要なテーマとなり、アマゾンウェブサービスやグーグル、マイクロソフトなどのクラウドベンダーは、各種データウェアハウスやデータレイクのソリューションに力を入れている。ところがクラウドベンダー純正のサービスがあるにも関わらず、欧米では「Snowflake」や「Databricks」といった新しいサービスが注目を集め、市場から高い評価を得ている。既存のデータ活用ソリューションと何が違い、なぜ注目されているのか。そして日本では今後どのように展開されるのか。それぞれを提供するスノーフレイク、データブリックスの日本法人とパートナーに話を聞いた。
(取材・文/谷川耕一 編集/日高 彰)
企業のデジタル変革では、データ活用が鍵となる。デジタル化で集められたデータを分析し、新たな知見を得てそれを使いビジネスに価値をもたらす。
データの活用自体は1990年代には既にデータウェアハウス(DWH)の最初のブームがあり、その後も何度かビジネスインテリジェンス(BI)が注目され、2010年頃からはビッグデータが新たなキーワードとなった。そして構造化データに加え、非構造化・半構造化データなどあらゆるデータを蓄積するデータレイクにも注目が集まった。
しかし、ため込んだ膨大なデータを活用するのは容易ではなく、データレイクの取り組みが上手くいった企業は少ない。当初のデータレイクはNoSQLデータベースやHadoopなどの新しい技術を必要としたため、多くの企業で経験のないそれらの基盤をオンプレミスに構築し運用するのは容易ではなかった。また、データが爆発的に増えたことで十分な処理性能を発揮するのも簡単ではなかった。
オンプレミスのデータレイクはなかなか上手くいかなかったが、クラウドの拡張性を生かし、膨大なデータを活用する環境をクラウド上で構築する動きが注目されている。クラウドであれば運用管理に手間がかからず、性能や容量が足りなければ拡張するのも容易だ。
Snowflake
クラウドのメリットを100%引き出すデータプラットフォーム
クラウドに最適化してゼロから構築されたDWH
米スノーフレイク共同創業者のブノワ・ダジビル氏とティエリ・クルアネス氏は、以前オラクルで大企業のDWH統合案件などを支援しており、オンプレミスベースの大規模DWHの初期費用が高額で、ノード追加にも多大な手間がかかるのが課題だと感じていた。一方スノーフレイクを創業する2012年頃から、DWHをクラウドで構築する動きも出始めていた。当初のクラウドDWHはオンプレミスのものをクラウド上に載せただけで、クラウドの本質的な良さは発揮し切れていなかった。そこで最初からクラウドに最適化した製品を提供しようと考え、Snowflakeを生み出す。
「Snowflake以外のクラウドDWHの仕組みは、大量データのローディングもダッシュボードからの多くのユーザーアクセスも、データサイエンティストのアドホックな分析も、一つのクラスタで捌こうとしている。これには無理がある」と言うのは、スノーフレイク日本法人の本橋峰明・ソリューションアーキテクトだ。クラスタが一つだけだと、たとえばデータサイエンティストが重たい処理を実行すれば、他との競合が発生し処理は遅くなる。
続きは「週刊BCN+会員」のみ
ご覧になれます。
(登録無料:所要時間1分程度)
新規会員登録はこちら(登録無料) ログイン会員特典
- 注目のキーパーソンへのインタビューや市場を深掘りした解説・特集など毎週更新される会員限定記事が読み放題!
- メールマガジンを毎日配信(土日祝をのぞく)
- イベント・セミナー情報の告知が可能(登録および更新)
SIerをはじめ、ITベンダーが読者の多くを占める「週刊BCN+」が集客をサポートします。 - 企業向けIT製品の導入事例情報の詳細PDFデータを何件でもダウンロードし放題!…etc…



